在公司内部 做算法分享 的目录
CS算法数据结构基础 DSA
- 一般相对于算法, 软工积累才是第一位的, 各种书单 <代码大全>
- 选择 书 优先于ppt (快餐垃圾食品) 网上没有什么好的PPT.
软件工程师 学习这些基础算法的意义
- 理解了解 数据结构原理, 知道什么时候该用什么.
- 学习借鉴 解决经典问题的算法的思想. // 活学活用胜过生般硬套.
练习的意义 lintcode
- 模拟各种 小场景和小问题, 锻炼代码能力和准度.
- 首要的学习途径是做 (解决, 构建). Do IT is the only way to learn program. 70%.
学习方式, 讲结构和原理
DSA 划定的范围
- 行业里 大公司对工程师最最基本的要求范围.
- 一些财富开拓性的公司会要求更高, 明星创业公司.
- 网易游戏(有道难题), 金融交易 量化派交易 的程序员要求简直…. 已经超纲, 天外有天.
工程基础
- 链表 队列 栈 位的操作 最低位
- 两个有交叉的链表, 找到其交叉的地方.
- 括号匹配 进阶词法解析 最小值进出都是O(1)
- 冒泡排序 选择排序 插入排序 复杂度评估
- 快排 切分 复杂度评估 求一个数列的k大数
- 归并排序 分治(递归) 归并求差异
- 堆排序 优先队列, 常有删插的数列维护一个中值
- 希尔排序 (特点 交换的距离)
- 基数排序(桶排序) 百度百科 计数排序
- 外部排序 多路归并(切分) 多个关键词搜索
- 哈希扩容 LinkedHashSet复合结构
- 生成排列 复杂度 根据已有排列生成下一个排列
- 深搜 八个皇后 棋类AI简单应用
- 广搜
- 二分查找 两个排序数列求中值
- 排序树的查找 广泛应用索引查找
- 二叉树的常见操作 层级遍历 和为指定值的路径 两个叶子节点的第一个公共节点
- 二叉树非递归遍历 排序树索引遍历
- 平衡排序树 一些平衡树的增删改查复杂度
- 动态规划 int数组统计bit位 最长公共子序列 最长回文串
- 背包问题 100个数字, 分两组,和差最小
- 贪心 哈夫曼编码问题
一些应用和例题
- mysql引擎一些优化 文章
- ssdb根据其算法结构做性能评估 文章
- 已有一个字典 和 去掉空格标点的字符串 iloveyou, 给出一种恢复方案
- 搜索应用 倒排索引, 搜索引擎中遇到的种种问题
- 很长的一片文章, 敏感词过滤
- 分治典型 大数据文件 求最大的100个数
- 青蛙过河 现在给你河的宽度,河中石头的个数(青蛙要从石头上跳过河,这些石头都是在垂直于河岸的一条直线上) 还有青蛙能够跳跃的 最多 的次数,还有每个石头离河岸的距离,问的是青蛙一步最少要跳多少米可以过河
高级工程基础
- 跳跃表 物美价廉(实现简洁, 性能不错)
- 前缀 后缀数组 矩阵快速乘法
- 字典树
- 线段树
- 图论
- 拓扑排序 工程中常见的循环依赖
- 最小生成树 并查集 边排序 贪心 最短路 Dijkstra bellman ford 多源最短路
- 最小连通量
- 网络流 增广路
- 二分图
- bloom filter
- 红黑树 内置结构中
- B+树 数据库类软件中, 广泛应用
- K-D树 附近的点 半径R内 最近的K个 维度归类 Quora
-
KMP AC自动机
- 数论(欧几里得, 快速乘法, 大素数分解, RSA) 略
- 计算几何 略
mapper reduce的设计文档idea分享
复杂度函数的铺垫 – 比如 排序算法
- 算法执行路径,计算节点 是可以铺开的
- 其铺开的计算节点结构图 的面积大小(节点个数) 是和 处理规模n有函数关系
冒泡排序算法铺开是个等边直角三角形,面积正比于 n^2
快速排序算法铺开是个长方形,高一般是logn,宽n,面积是nlogn。糟糕的时候高是n, 形状是 等边直角三角形 - 铺开的面积大小 基本就是 计算量大小,也就是计算机的工作量, 正比于 计算完成时间 y。
- 也就说, 针对数据处理的规模n, 为到达目标 执行算法策略 完成的时间 y 正比于 一些函数曲线 (常见如 n!, 2^n, n^2, nlogn, n, log2, 1)
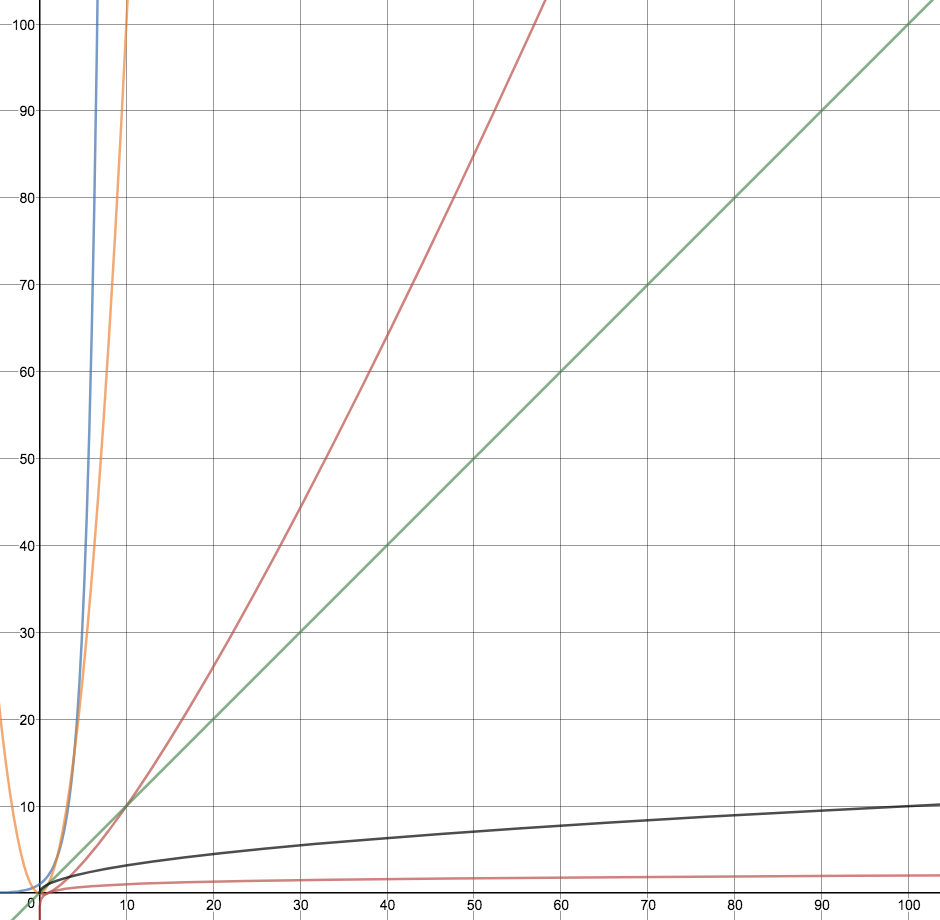
看看几个函数的趋势,x当作 算法处理数据规模,y轴就是我要等待的时间。
但对于计算机A, 一秒算10^12次, 无论计算量是3还是 1000, 时间都是毫秒 – 果然是计算机 !! 就像拔河我远远 逊于 我家 拖拉机.
- 处理规模在200以内。200以内算量不关心函数曲线
-
处理规模10000 的时候 对数log(x)贴着x轴,2^x 贴着y轴
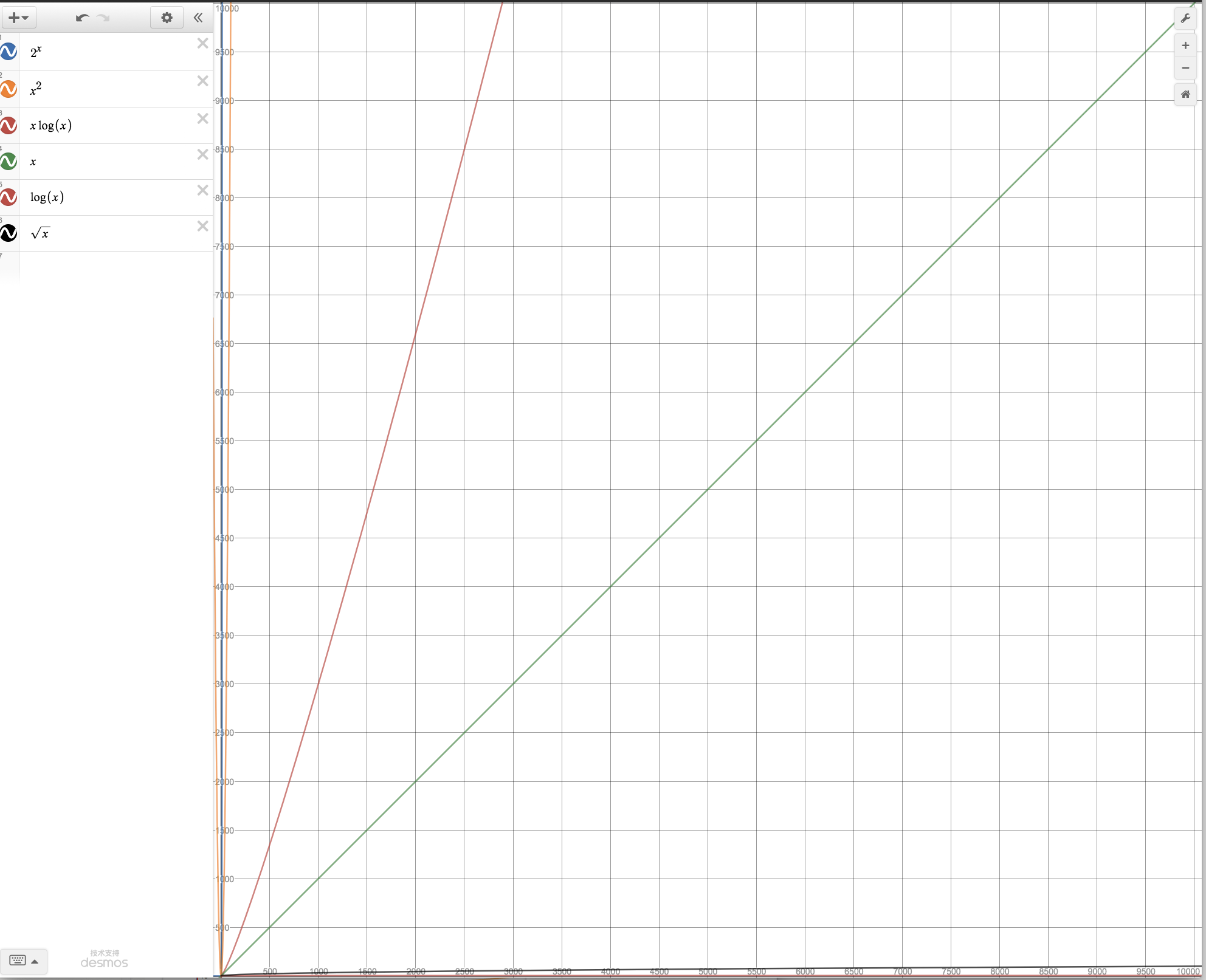 
 - 处理规模在100w的时候,贴着y轴的x^2 都让人看不到未来了, log(x) 贴着x走. x^2 = 10^12 VS xlog(x) = 210^7. 后者是前者的510^4, 后者计算机A用1秒, 前者是 5*10^4 秒, 将近14个小时. 也就是跑一晚上, 结果就出来了.
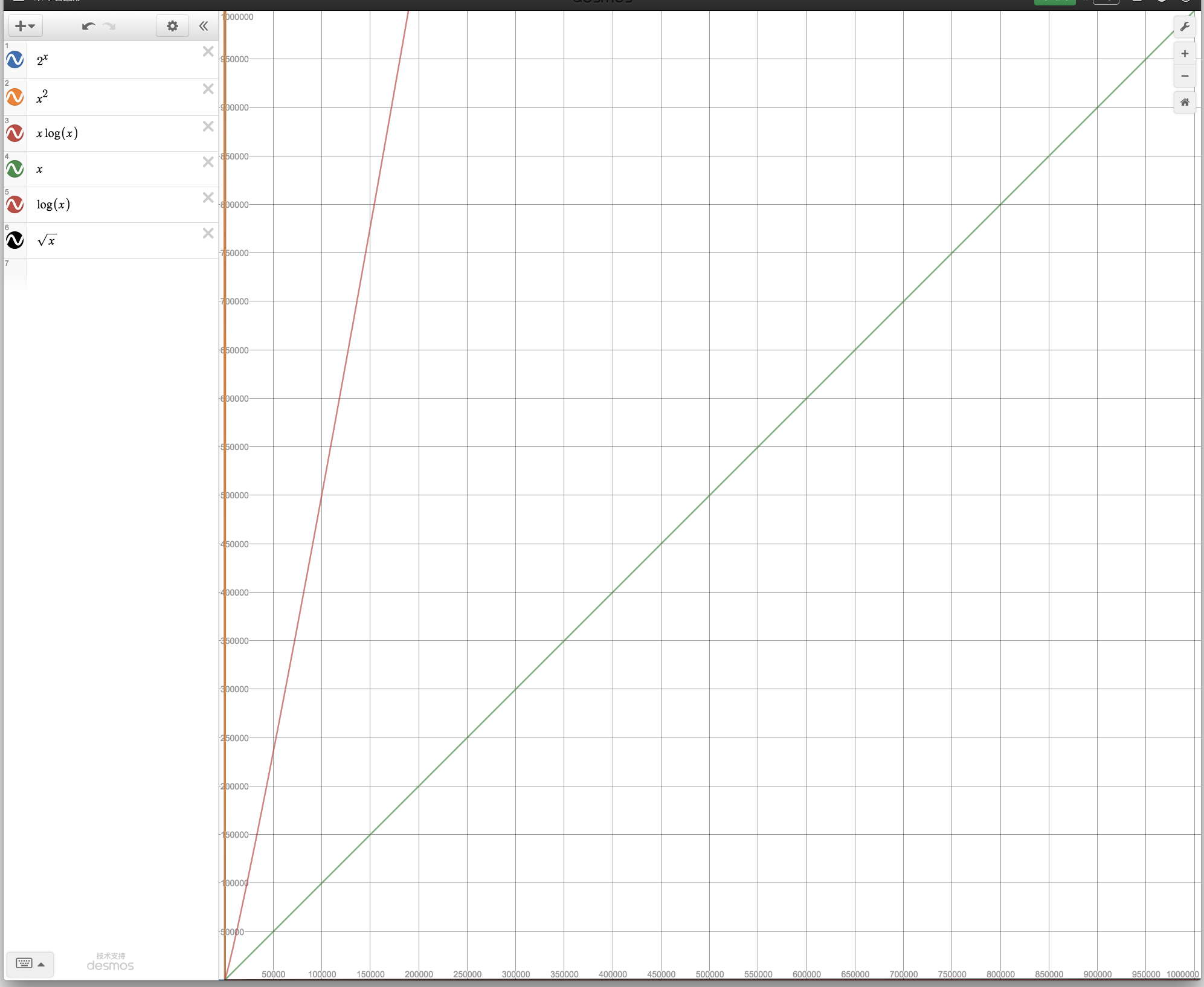
堆排序是算量nlogn, 100w的规模,我需要等几秒, 但是要是冒泡, 等得我遥遥无期, 直接关机.
1000w的时候, x^2 = 10^14 VS xlog(x) = 2.3 * 10^8. 倍差是 4.3*10^5 = 430 0000 .
前者 计算机A 200秒, 后者是不到10000天. 贫富差距就是这么拉开的.
无序线性数组中, 基于 元素比较交换的排序 的算法理论上限是 nlogn. 这经过数学证明了 – 神奇.